Posted by Sam on Jan 27, 2012 at 06:01 AM UTC - 5 hrs
Most online developer API services that I've used are set up as if the customer is also the software developer.
That should change.
As the software developer, I don't want to be the owner of my customer's accounts, and I don't
want to worry about trying to figure out how to transfer ownership (if your service allows it, that is).
Because of that, theres a lot of waste that goes on: wastes of my time,
which wastes my customer's or my company's money.
I'm saying "customer" here, but you might substitute that with "the person who really needs / cares about the account,"
because that person, in my estimation, is rarely the software developer. Unless I'm developing an app for myself,
I only care about that API because someone else needs me to. And even when I'm developing for myself, I hope it gets to
a point where I need to hire someone to care about it on my behalf, so I can focus on more important things.
The typical signup process for me goes like this:
More...
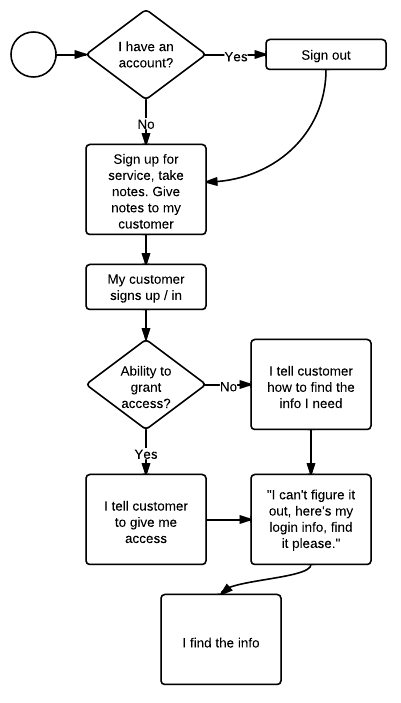
- Me: If I already have an account, sign out.
- Me: Sign up for the service. Find what I need to integrate with the API. Note the steps I perform.
- Customer: Signs up for the service, with me providing the steps they'll need to take.
- Me: Ask my customer to give me the info I need, or grant me access if that option is available.
- Customer: "I can't figure it out, here's my login info, find it please."
- Me: I find the info, and tell the customer to reset their password. I doubt they ever do.
You're offering the service, yet there's no "you" in that process.
Here's the process I'd like to see:
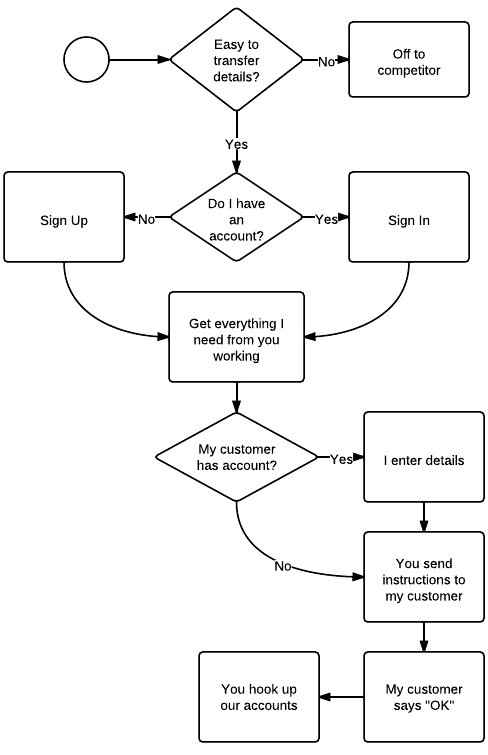
- You: Tell me I can easily transfer the account (or project or access keys) before I bother to sign up
- Me: Sign up for an account for myself.
- Me: Get everything working.
- Me and You: If I know my customer already has an account, provide a place for me to enter my customer's email address. If you offer more than one thing I'll need access to, let me indicate what I need for this project.
- You: Send detailed instructions of to grant access to my needs.
- You: If my customer does not have an account, you send them detailed instructions for how to sign up and what they'll need to know to get value from your service.
- Customer: signs up for their account, indicating they are actually working with me.
- You: Hook up our accounts, with me transferring ownership of that "project" to my customer.
There's a lot less of me and my customer in that process, and a lot more of you.
It's certainly more complex, but it's simpler for the people who matter: your users.
Remember, the software developer is often the one who makes recommendations as to which products to use. Make
it easier for me, and I'll be more likely to choose your service over a competing one.
post scriptum side note: I used Lucid Chart to do the flow charts. I really
like it, but given how rarely I've wanted to diagram online, I don't see myself becoming a paid
subscriber. What do you use?
Hey! Why don't you make your life easier and subscribe to the full post
or short blurb RSS feed? I'm so confident you'll love my smelly pasta plate
wisdom that I'm offering a no-strings-attached, lifetime money back guarantee!
Posted by Sam on Dec 09, 2011 at 06:13 AM UTC - 5 hrs
Suppose you have some awesome analytics tool that provides great value to a bank's customer, but
they need to interact with it through the bank's website, and you need to host the tool.
You already have the data you need for the analytics to work, and the only missing piece you're left
to consider is "how do I know to whom to show which data?"
The data is private, so you need to ensure you're not showing it to someone who's not authorized to see it.
More...
 Photo by pbkwee
Photo by pbkwee
Some more constraints:
-
You don't want to generate thousands of usernames and passwords that would create more burden for the
users (and force them to log in twice)
-
You can't hook into the bank's user system. (nor would you want to, since they'd still have to log in twice)
-
You want this to be reasonably simple for the bank to implement whatever they need to do to make it
work on their end.
To show it on their site, you decide to create a template-less app that they'll embed in an iframe.
So what authorization mechanism do you use to know who should see which data?
One idea I had was to simply restrict which IP addresses (to those of the bank) the app would respond to.
Then they could just request a page via HTTP and serve up our response. But in order to get that to work,
there's too much that needs to be done: we have to coordinate all URLs with whatever the bank decides
they should be, and they have to figure out whether to GET, POST, PUT, etc. back to us.
The next idea was to have a single page that is restricted by IP address (to those of the bank), where
they will make an HTTP request to receive a token that expires after some length of time (or at the bank's
request, if they hit another URL to invalidate the token). The bank includes the token in the iframe src
URL which lets you know whose data to show.
But I'm really interested in hearing your thoughts. How would you do it? Is there a
standard way of doing this already?
Posted by Sam on Jul 26, 2011 at 01:51 PM UTC - 5 hrs
I'm working on a website analytics tool, and in pursuit of that goal, I wanted to POST some data from a series of websites to the one that's doing the tracking. If you've tried to do that before, you've run afoul of the same origin policy, as I did, so you'll need to specify how your application handles Cross-Origin Resource Sharing.
I won't go into all the details about why that is the case - for that you can read the Wikipedia links above. Instead, I'm going to show a short example of how I handled this in my Rails 3 app.
First, you need to specify a route that will handle an HTTP OPTIONS method request.
# config/routes.rb
resources :web_hits, :only=>[:create]
match '/web_hits', :controller => 'web_hits', :action => 'options', :constraints => {:method => 'OPTIONS'}
More...
Since this controller only handles incoming requests to create a web hit resource, I've only specified the POST method on the it (which will run the create method in the controller). However, before the browser will send the POST to the tracking website, it first sends an OPTIONS request to see if it can do the POST. The second line specifies the route for that: it will go to my web_hits_controller and use the action options.
Next, we'll look at the controller.
# controllers/web_hits_controller.rb
class WebHitsController < ApplicationController
def create
if access_allowed?
set_access_control_headers
head :created
else
head :forbidden
end
end
def options
if access_allowed?
set_access_control_headers
head :ok
else
head :forbidden
end
end
private
def set_access_control_headers
headers['Access-Control-Allow-Origin'] = request.env['HTTP_ORIGIN']
headers['Access-Control-Allow-Methods'] = 'POST, GET, OPTIONS'
headers['Access-Control-Max-Age'] = '1000'
headers['Access-Control-Allow-Headers'] = '*,x-requested-with'
end
def access_allowed?
allowed_sites = [request.env['HTTP_ORIGIN']] #you might query the DB or something, this is just an example
return allowed_sites.include?(request.env['HTTP_ORIGIN'])
end
end
The key above is checking whether or not the request should be allowed. Here I've set access_allowed? to always return true, but you could have some checks in there that inspect the request to determine if you want to allow it or not. If you do, set the headers and respond appropriately. Since I don't need to really return a response, I'm only returning the headers indicating success or access denied, but you could just as easily turn those head method calls into renders if you need to render some content.
A good resource that helped me figure this out was Cross-Origin Resource Sharing for JSON and RAILS. He didn't go into detail on restricting access nor routing though, so I felt like this would be a good addendum.
Posted by Sam on Jul 30, 2008 at 12:00 AM UTC - 5 hrs
I put faith in web application development as an income source like I put faith in the United States Social Security system. That is to say, it's there now, but I don't expect to be able to rely on it in its current incarnation very far into the future.
James Maguire quotes Robert Dewar hitting the nail on the head:
More...
Java is mainly used in Web applications that are mostly fairly trivial. If all we do is train students to be able to do simple Web programming in Java, they won't get jobs, since those are the jobs that can be easily outsourced. What we need are software engineers who understand how to build complex systems.
Although Dewar was speaking in terms of Java, the statement applies to the broader world of web apps (and many desktop apps) in general.
That property is precisely what allowed frameworks like Rails and Django to come into existence and get popular.
Soon enough, the money will dry up for implementation because it's too easy to generate solutions for most problems you'll encounter - either using a framework, or a content management system like Sharepoint or Joomla, or even by hiring someone to generate it for you. Yesterday I recommended a potential client just go the CMS route.
Nowadays, most of the skill involved in writing web applications amounts to gluing the disparate pieces together. How long until someone figures out how to commoditize that? Instead of knowing only how to implement solutions to problems, you need to be skilled at problem solving itself.
Right now, you might be in a position where you can kick back and count your money while you smoke a cigar.

But if you're in the business of building web applications and you're not innovating new kinds of them, you're doomed. You can chase vertical after vertical and keep building the same apps for quite a while, but if you don't get into generating them, you're on the way out as people come in who can do it cheaper than you and with higher quality.
Generation is to web apps as prefabricated steel buildings are to construction. Except almost no one cares if their web application was generated or not - they just want the lower price.
I suspect that even if you are generating applications, at some point in the future, the number applications needing to be generated will not have grown as quickly as the number of people who can generate them.
People are building complex data warehouses and doing analysis and reporting on them with GUIs and Wizards right now. You still need the knowledge pertaining to data warehouses, but that knowledge is becoming easier to obtain for more people with less effort than ever before. That trend, which fits in with the general trend of information democratization, is unlikely to reverse itself.
If you don't plan for change now, you'll end up shocked.

And then how long until you're pulling out the cloth-eared elephant?

What Dewar said is true: Web applications are mostly fairly trivial. To survive,
you need to learn the fundamentals so you are applicable in various kinds of programming and for different platforms. If you really want to be safe, you need to be innovating, not building copy-cat applications with a twist (and especially not from scratch?!?!).
Giles Bowkett put it well when he described the effects of incompetent programmers' entry into a particular market:
Every programmer should also read Chad Fowler's "My Job Went To India" book, where he explains that as larger and larger numbers of programmers adopt a particular skill, that skill becomes more and more a commodity. Rails development becoming a commodity is really not in the economic interest of any Rails developer. This is especially the case because programming skill is very difficult to measure, which - according to the same economics which govern lemons and used-car markets - means that the average price of programmers in any given market is more a reflection of the worst programmers in that market than the best. An influx of programmers drives your rates down, and an influx of incompetent programmers drives your rates way the fuck down. (Bold emphasis mine)
The problem, in my view, is that the influx of incompetent programmers is inevitable.
So building well-known applications with twists becomes much like the would-be artist who looks at Pablo Picasso's work and says, "I could do that."
The obvious exception is that applications are not (usually) like art. Well-made knockoffs of the original aren't likely to be differentiable by customers from the cheap knockoffs, so the masses of incompetents and maybe the original end up defining the market in the long term.
After you've seen it, you could do this:

To which we all respond, "But you didn't, did you?"
As always, I welcome your thoughts in the comments below.
Posted by Sam on Mar 17, 2010 at 03:27 PM UTC - 5 hrs
I was having trouble with dragging and dropping elements using Scriptaculous's dragdrop.js. Apparently,
I'm not the only one.
The problem was:
I have a div with overflow = auto, so when there is more content than the size of the div, scrollbars appear.
My draggables and droppables are all elements inside of that div. Everything works fine when the scrollbar is
scrolled all the way to the top, but when you scroll it down any amount, the draggables fail.
More...
There are plenty of potential solutions out there, but none of them worked for me. I would get the scrolling working, and then the
draggable would move away from the cursor. I'd get it in sync with the mouse cursor and the scrolling would get crazy again.
I'd fix that and then no matter where I dropped it, if the div had been scrolled, dropping would fail.
Here's how I fixed the problem:
-
In the
Draggable#updateDrag function (~ line 356), on the first line, I changed the value of the pointer argument to
take into account how much the container had scrolled:
pointer = new Array(pointer[0] + this.options.scroll.scrollLeft, pointer[1] + this.options.scroll.scrollTop);
At least one of the solutions I recall seeing mentioned this.
-
In the same function, I changed the first two elements in the
p array before the last two elements get
pushed onto it:
p = new Array(p[0] + this.options.scroll.scrollLeft, p[1] + this.options.scroll.scrollTop);
This also just takes into account how far the container has been scrolled.
-
To ensure my droppables were able to receive the draggables given the adjusted coordinates, we need to adjust the
scroll position just as we did above. First, I adjusted the code in my webpage that produces the droppables and
added a scroll parameter that should be the name of the element that scrolls (the same parameter the draggable accepts):
Droppables.add('slot_1_7_2', { scroll: 'weeklycalendar' });
Since Droppable elements don't generally take a scroll option, we'll need to modify that code in Scriptaculous's dragdrop.js
file as well. In the Droppable#fire function (~ line 109) add the folling lines under Position.prepare();:
var point = [Event.pointerX(event), Event.pointerY(event)];
if(this.last_active.scroll){
point[0] += $(this.last_active.scroll).scrollLeft;
point[1] += $(this.last_active.scroll).scrollTop;
}
Finally, just underneath that where it calls this.isAffected, change the first parameter from
[Event.pointerX(event), Event.pointerY(event)] to use the variable we created above, pointer.
That should be it. If you've tried the above and still get problems, feel free to leave a comment below, or
contact me and I'll do my best to help out.
I haven't submitted a patch because I didn't check to see that this was a general solution. It seems like it should be, but
without testing it outside my intended usage, I don't think it'd be accepted anyway. Quite frankly, I'm not thrilled about
adding a new option to droppables, but it seemed like the simplest route to fix my problem at the time.
Yes, I tried setting includeScrollOffsets to true and using Position#withinIncludingScrolloffsets
in Prototype, and that failed for me too.
Posted by Sam on Nov 07, 2008 at 12:00 AM UTC - 5 hrs
It was a sunny day in October, and Origin Shabamtech's web site had crashed for
the umpteen millionth time. Mr. Shabam, the company's
CSO, was desperate.
The money they were making from the website was great - processing
seven figures monthly - but it wouldn't continue if the application kept crashing.
More...

"We have to get this website to stay up," he said to himself. "But how?"
Mr. Shabam called on his company's hosting provider, Boomtastic Server Company (BSC)
to see if they could help.
They'd be glad to provide the servers and bandwidth, but that wasn't
going to help unless the application itself could be split among the servers. With
only an executable file and associated DLLs, and VulpesPro being the
point-straight-to-the-file-non-ODBC database, that looked bleak.
The source code was unavailable, as was the original vendor.

In fact, the situation seemed so impossible that BSC referred Origin
Shabamtech to one of its resellers, Gulfomatic Solutions, and its team of
Elite Engineers started a betting pool against Gulfomatic.
Luckily, Origin Shabamtech had
a virtually unlimited supply of licenses -- which was about the only part
of the problem going in their favor.
Gulfomatic's team of Solutioneers were eager to dig into the problem, and hopes were
high that they could show up their Elite colleagues and prove their doubt as
misguided. The Solutioneers worked day and night for a fortnight,
coming up with several potential solutions, in order of increasing complexity. With
each new trial, the Beast of a problem revealed new defenses. Yet in doing so, it also
revealed tiny bits of information about its weaknesses.

After the third attempt at an architectural fix, one of the Solutioneers spotted the
unshielded thermal exhaust port of the Problem Beast. The team worked until the
wee hours of the morning, hacking away as they tried to bring the beast down. But
the problem was able to route energy to shore up the points of attack.
Undeterred, Solutioneers brought out their arcane weaponry of packet sniffers
and decompilers. The onslaught continued.
And it was a good thing. The next morning, a few hours after sunrise, the Beast was slain, and the
Solutioneers held their heads in triumph. They stood victorious, as their
victim lay at their feet.
To this day, the myth of Gulfomatic's solution
remains a complete mystery.
I want to figure out the mystery. Do you have any ideas? How would you determine what's causing the site to crash? What might you look at? What might you do to fix it? Let's discuss it in the comments. Don't be afraid to offer "stupid" suggestions - I don't think many of us would know where to start, much less how to proceed.
It may be somewhat server related, but it's not outside the realm of what I think programmers should (at the least) have a passing familiarity with.
Update: As Markus Prinz pointed out to me, the point of this isn't all that clear, so I reworked the paragraph above to include questions that (I hope) give more direction toward the discussion I'd like to start.
The plan is to write another post discussing some of that, but for now I wanted to get your responses and discuss them here (and if you don't mind, potentially quote them in a future post).
Last modified on Mar 14, 2015 at 01:23 PM UTC - 5 hrs
Posted by Sam on Jan 29, 2008 at 04:18 PM UTC - 5 hrs
It's been just over one year since I got excited about Arc.
Luckily for the language dorks, Paul Graham announced the release of Arc the language today.
There's even a tutorial suitable for beginners to Lisp.
I hope to have it installed and running a very simple web app by the end of the week. Work and school are calling though (and house-hunting and other things), so I may need to use my open source time to check it out.
Unfortunately, Paul says "we're giving notice in advance that we're going to keep acting as if we were the only users. We'll change stuff without thinking about what it might break, and we won't even keep track of the changes." So don't go building anything serious.
Best quote on reddit? " Someone somewhere invented a vaporware condensation machine and has been running it...."
In any case, let me know if you're going to be playing with it.
Posted by Sam on Jan 22, 2008 at 05:26 AM UTC - 5 hrs
I know, I know - everyone has big monitors now.
But with 1900+ pixels, I keep half for the browser and half for other stuff. If you go with 1000+ pixels, it doesn't leave me with enough room for my other apps, and I've got to (ack!) scroll sideways. It's not as bad with the ball on the Mighty Mouse, but most people don't have
one and it's not exactly effortless even with one.
What do you think?
|
Me

|
